

Negli ultimi anni, diverse tecniche di apprendimento automatico ed in particolare di deep learning, sono state usate per ottenere in modo massivo una varietà di interessanti ed importanti indicatori sulle caratteristiche dell’ambiente urbano. Oltre che in virtù dei progressi nel campo degli algoritmi e della maggiore accessibilità di risorse computazionali, questo tipo di applicazione è ora possibile grazie alla disponibilità di big data georeferenziati, spesso aperti, di diversa natura e provenienti da più fonti, come i dati da OpenStreetMap, i dataset di immagini a livello stradale (ILS) da Google Street View o Mappillary, nonché dataset di immagini aeree.
Tra le applicazioni di maggior successo del deep learning sono da annoverare certamente quelle nel campo della visione artificiale, tipicamente basate su reti neurali convoluzionali. In questo campo, i problemi tipici sono la classificazione delle immagini, il rilevamento degli oggetti e la segmentazione di entità. Nel compito di classificazione interessa ottenere le etichette di tutti gli oggetti rilevanti presenti in un’immagine, anche allo scopo di individuare e classificare automaticamente la scena o il contesto. Invece, nel caso del cosiddetto object detection si chiede alla rete neurale artificiale la posizione degli oggetti riconosciuti in termini di riquadri di delimitazione. Un caso ulteriore è rappresentato dalla segmentazione dell’immagine, in cui la rete viene addestrata a determinare il confine esatto degli oggetti. Da un punto vista pratico esistono due tipi di segmentazione: quella semantica, in cui non si differenziano diverse istanze dello stesso oggetto, e quella per istanza, in cui si vuole assegnare un’etichetta univoca a ogni istanza di un particolare oggetto nell’immagine.
Ad esempio, in Figura 1 sono rappresentati possibili output di reti convoluzionali applicate ad una immagine a livello strada di una nota via di Cagliari. Nel caso A, ad una rete addestrata sul dataset COCO (Common Objects in Context) è stato chiesto di individuare e marcare con dei box gli oggetti riconosciuti. Nel caso B, ad una rete addestrata sul dataset Places è stato chiesto di individuare la scena e i relativi attributi, sempre tra quelli appresi in fase di addestramento. La categoria di scena rilevata è ‘street’ e gli attributi sono risultati essere: man-made, natural light, open area, driving, asphalt, sunny, biking, pavement, transporting. La figura mostra, con una mappa di colore, le aree che hanno maggiormente pesato nella fase di classificazione. Nel caso C, una rete addestrata sul dataset CamVid (Cambridge-driving Labeled Video Database) è stata usata per la segmentazione semantica. Come si vede, la rete ha correttamente individuato tutte le categorie rilevanti.

Indipendentemente dall’applicazione, l’impiego di una rete convoluzionale partendo da zero richiede enormi dataset e considerevoli potenze di calcolo per la fase di addestramento. Si tratta infatti di apprendimento supervisionato di modelli spesso caratterizzati da milioni di parametri che devono essere determinati fornendo all’algoritmo di apprendimento sufficienti “esempi” dell’associazione tra immagine e etichette. Nel caso della segmentazione, per implementare un’applicazione basata su immagini che rappresentano contesti urbani, sono disponibili sia dataset di training, come Cityscapes, CamVid, o Mapillary Vistas Dataset, che reti neurali efficaci e pronte all’uso, come la Pyramid Scene Parsing Network (PSPNet) o la DeepLab-v3+. Ad esempio, è facile trovare reti già addestrate sul dataset Cityscape composto da migliaia di immagini e decine di categorie di entità caratteristiche di un ambiente urbano come strada, marciapiede, parcheggio, persona, ciclista, edificio, muro, recinzione, vegetazione, ed altri. Per applicazioni più specifiche, come il riconoscimento di particolari caratteristiche dell’ambiente urbano, o per la segmentazione di entità non previste nelle reti già addestrate disponibili, è generalmente necessario uno specifico addestramento della rete che comporta la creazione di un cospicuo dataset di immagini classificate. Fortunatamente, la numerosità del dataset di addestramento può essere contenuta con la cosiddetta tecnica del transfer learning, che consiste nel partire da una rete neurale già addestrata su un dataset molto più grande e nel limitarsi alla fase di apprendimento degli ultimi strati. Si tratta, in estrema sintesi, di una tecnica per recuperare la capacità di una rete neurale di estrarre le caratteristiche rilevanti da un’immagine per poi specializzarla su un training set diverso e, normalmente, molto più piccolo.
Come già osservato, il contesto sopradescritto ha favorito negli ultimi anni lo sviluppo di una enorme quantità di studi che si sono avvalsi del deep learning applicato a immagini di aree urbane. Il numero delle diverse applicazioni è troppo grande per menzionarle tutte qui e un panorama più ampio può essere trovato in (Biljecki e Ito, 2021).
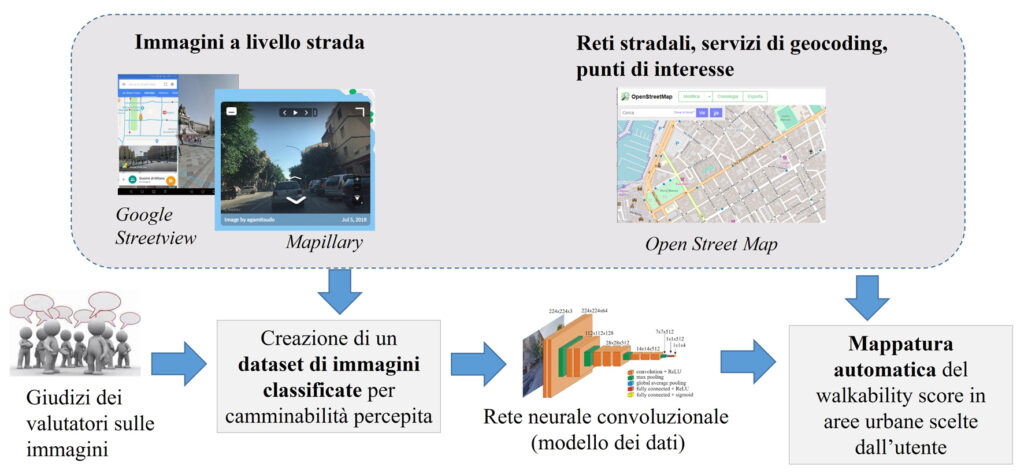
L’uso congiunto di deep learning e ILS si è rivelato particolarmente utile negli studi di valutazione automatica della camminabilità delle strade di un’area urbana. Le applicazioni in questo specifico campo sono ormai molte e basate su approcci diversi. Alcuni studi si concentrano su aspetti specifici che sono rilevabili dalle immagini e che vengono considerati come influenti sulla camminabilità. Ad esempio, la sicurezza percepita da un pedone, il ruolo dello stile architettonico degli edifici, la presenza e dimensione dei marciapiedi, la cartellonistica, il verde urbano, l’effetto canyon e, in generale, tutti gli elementi ricavabili da immagini. Spesso viene definito un indice che si basa sulla combinazione dei diversi fattori rilevati. Altri studi puntano a determinare in modo automatico uno score complessivo della camminabilità percepita da un potenziale pedone. Da un punto di vista delle tecniche di deep learning, la segmentazione semantica viene usata in molte applicazioni per il riconoscimento di elementi specifici nell’immagine (ad esempio edifici, cielo, marciapiede, alberi). Una volta individuati gli elementi, viene calcolato il loro peso percentuale e definito un indice, eventualmente da usare in combinazione con altri. Il vantaggio della segmentazione automatica, come già ricordato, è che generalmente la rete neurale è disponibile già addestrata per lo scopo. Un’altra tecnica, usata in modo congiunto o alternativo alla precedente, consiste nell’impiego della rete neurale come surrogato della cognizione visiva umana. A tale scopo, nella fase di addestramento supervisionato non si forniscono alla rete specifici elementi da riconoscere ma bensì un punteggio di camminabilità complessiva associata all’immagine e le si lascia il compito di individuare le caratteristiche che hanno portato a quel punteggio. In questi casi è necessario un addestramento della rete su adeguati dataset di immagini classificate per punteggio di camminabilità, oltre che una certa potenza di calcolo. Fortunatamente, la numerosità dei dataset di addestramento può essere contenuta con la già menzionata tecnica del transfer learning. Ad esempio, nel campo della classificazione automatica della camminabilità percepita, molte applicazioni partono da reti originariamente utilizzate per riconoscere le scene nel dataset Places che contiene centinaia di categorie di scene e milioni di immagini già etichettate. Nella valutazione della camminabilità, l’integrazione tra deep learning applicato a immagini georeferenziate e l’informazione proveniente da dati non visuali, come quelli provenienti da OpenStreetMap (ad esempio le caratteristiche delle strade o i punti di interesse), ha portato alle più convincenti applicazioni di valutazione massiva. Lo schema operativo è quello rappresentato in Figura 2: un dataset di training viene usato per produrre una rete addestrata che poi può essere usata a piacere su nuovi dati per la valutazione.
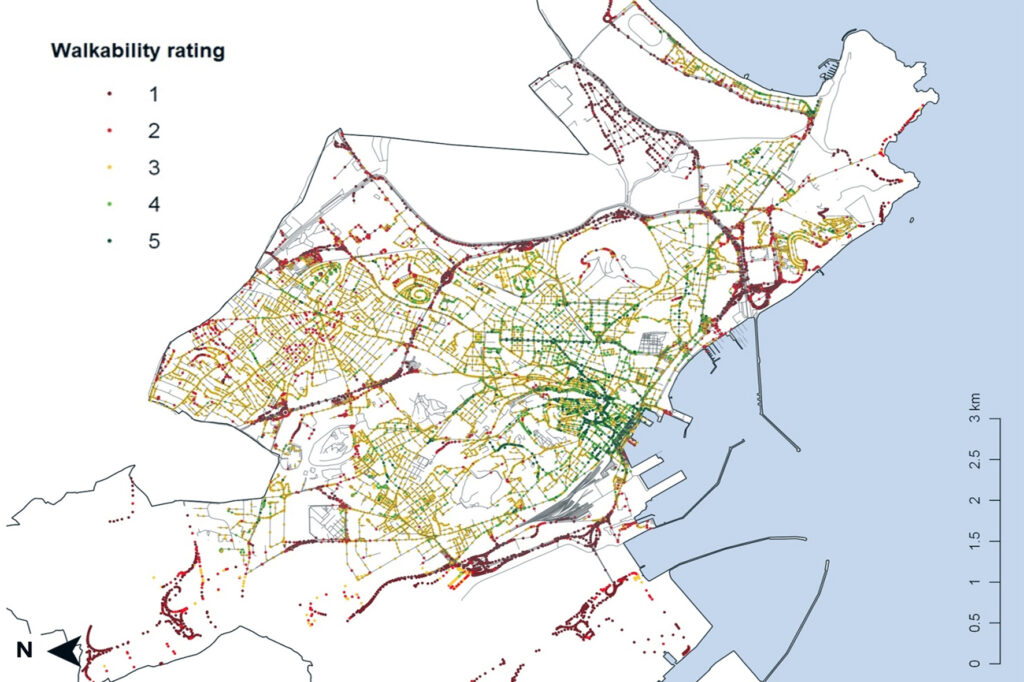
A titolo di esempio, in Figura 3 è rappresentata una mappa di migliaia di punti corrispondenti ad immagini valutate automaticamente per il calcolo del cosiddetto Capability-Wise Walkability Score (CAWS) eseguito in (B lecic ed altri, 2018). L’indice CAWS è poi stato calcolato considerando la stima della camminabilità degli archi stradali in combinazione con informazioni specifiche sull’accessibilità di significative categorie di funzioni urbane.
Gran parte delle applicazioni del deep learning sulla valutazione automatica della camminabilità si basano su ILS che presentano un notevole vantaggio se l’obiettivo è quello di valutare ciò che vedono e percepiscono i pedoni. Tuttavia, molto promettente sembra l’uso combinato del deep learning, ILS ed altri dati rilevati a distanza, ad esempio mediante droni, che ormai consentono l’efficace generazione di ortofoto 3D e immagini RGB-D.
Ulteriori approfondimenti
- Filip Biljecki, Koichi Ito (2021): Street view imagery in urban analytics and GIS: a review, Landscape and Urban Planning, vol. 215 Doi: 10.1016/j.landurbplan.2021.104217
- Ivan Blecic, Arnaldo Cecchini, Giuseppe A. Trunfio (2018): Towards Automatic Assessment of Perceived Walkability. LNCS vol 10962, pp. 351-365 Doi: 10.1007/978-3-319-95168-3_24
- Yunqin Li, Nobuyoshi Yabuki, Tomohiro Fukuda (2022): Measuring visual walkability perception using panoramic street view images, virtual reality, and deep learning, Sustainable Cities and Society, Vol. 86. Doi:1016/j.scs.2022.104140